Property-based Testing For The Rest Of Us (or: The Natural Next Step After TDD)
It’s no secret that getting started with Property-Based Testing (PBT) is hard. This series of articles does not have the presumption of changing this fact. It is merely the outcome of the observations and thoughts I have gathered during my personal journey.
By no means is this a comprehensive manual. Consider it as a friendly introduction to help dispel the fear.
I will rely on C# examples with FsCheck, although my heart is with Hedgehog.
All the code samples are on GitHub.
Note: do you prefer to start directly with a practical example? Go straight with the 4th installment.
Index
- Utterly opinionated introduction to Property Testing
- Shut up and code!
- It’s properties all the way down
- Property-driven Development
Utterly opinionated introduction to Property Testing
- Property Testing! What’s the fuss about?
- Why is it powerful?
- Show me the code
- So, define Property-based Testing
- Too good. Where’s the catch?
- Say random again, say random again, I dare you!
- Going Beyond Fixtures
- All right, but the
[Food]attribute does not exist. - Notes
- References
- Comments
Note: while discoursing about PBT, I will refer to the traditional way of writing tests as TDD: although not an accurate definition, please indulge me for the sake of conciseness.
Property Testing! What’s the fuss about?
There is no fuss at all. Property Testing is a niche discipline. It’s almost unknown outside the tiny world of Functional Programming. And this is a pity, because it is amazingly powerful, effective and rewarding.
In the Haskell world it is very popular thanks to QuickCheck, the grandfather of all the PBT libraries. In other ecosystems it is not given the attention it deserves.
Why is it powerful?
Many would tell you it is because it’s great at catching bugs. Some will stress how it similar to fuzzing testing in the way it randomizes the input values.
While all the above are true, I prefer to think I love it for a third reason: it elevates your comprehension of the domain.
Domain Experts communicate with us developers on 2 different levels. First, they express the business rules using abstract and strict statements:
| Abstract rules |
|---|
| “The catalog always lists products in alphabetical order” |
| “Account names are unique and case insensitive” |
| “We never apply more than 1 discount promotion to a single purchase; we always select the most convenient discount” |
Then, to help us understand, they also provide us with some examples:
| Concrete examples |
|---|
| “With alphabetical order I mean: Muffin, Coffee, Milk shall be printed as Coffee, Milk, Muffin” |
“About account names, you cannot have 2 “john.doe”. “ john.doe” and “John.Doe” are the same account |
“Say a customer purchases 2 cups of coffee, 1 milk and 1 muffin for 4 people.4 people are entitled for Promotion 1, 20% discount, 1 EUR.Milk and Muffin activates Promotion 2, 0.8 EUR.In this case, we apply Promotion 1” |
Both levels are important.
On the one hand, abstract rules are
very powerful, because they are concise and they have a general
application.
On the other hand, the examples — which are
derivated from the abstract rules — ease the comprehension.
Unfortunately, when it comes to translating requirements to tests, we only code with examples. Not only is this risky — after all, the application must work in all the cases, not exclusively in the few ones covered by the examples — it is also a lost opportunity, a loss of information in the communication between business and development.
Indeed, we rarely do any effort for expressing the rules in their more
general form.
Not our fault. We don’t because the tools provided
by TDD are very much example-based. It’s mostly a technical
limitation: we just don’t know how to translate "products are always
sorted alphabetically" without resorting to a specific list of
products.
If TDD is about coding examples, Property-based Testing is about
coding the pure rules.
PBT provides a way to express the business
functionalities abstracting from the specific examples. In a sense, to
capture their core essence.
That’s exactly the selling point of PBT: it leads you to deepen your understanding of the domain problem by forcing you to write statements independent from specific anectodal cases.
As a side effect, you will get an excellent tool for catching nasty bugs and, most likely, a lot of fun.
Show me the code
OK, I see you are impatient. Here we go. I will give you some examples. I don’t expect you to understand them just yet. Just try to catch the gist of them. In the next pages we will delve more into details.
Given the following integration test:
record Product(Guid Id, string Name, Category Category, decimal Price);
[Fact]
void products_can_be_persisted()
{
var product = new Product(
Id: Guid.NewGuid(),
Name: "The Little Schemer",
Category: Books,
Price: 16.50M);
_repository.Save(product);
var found = _repository.LoadById(product.Id);
Assert.Equal(found, product);
}
the equivalent Property-based one would be:
[Property]
bool all_products_can_be_persisted(Product product)
{
_repository.Save(product);
var found = _repository.LoadById(product.Id);
return found == product;
}
Basically, the same test, without the specific value for Product.
This does nothing to “capture the essence of requirement”, though.
As a second case, here’s a xUnit Theory for the Fizz Buzz Kata:
[Theory]
[InlineData(15)]
[InlineData(30)]
[InlineData(45)]
[InlineData(60)]
void multiples_of_15_return_fizzbuzz(int multipleOf15)
{
Assert.Equal("fizzbuzz", fizzbuzz(multipleOf15));
}
This can be directly translated to
[Property]
Property all_the_multiples_of_15_return_fizzbuzz()
{
var multiplesOf15 = Arb.From(
Arb.Generate<int>()
.Select(i => i * 15));
return Prop.ForAll(multiplesOf15, n => fizzbuzz(n) == "fizzbuzz");
}
Better. ForAll(multiplesOf15, n => fizzbuzz(n) == "fizzbuzz"); is a
direct and honest translation of the requirement All the multiples of
15 return "fizzbuzz".
As some more complex examples, let’s translate 2 of the abstract rules we mentioned before:
| Abstract rules |
|---|
| “Account names are unique and case insensitive” |
| “We never apply more than 1 discount promotion to a single purchase; we always select the most convenient discount” |
“Account names are unique and case insensitive”
A possible implementation is:
internal record Employee(string FirstName, string SecondName);
internal static class AccountNameGenerator
{
private static string Generate(Employee employee) => ...
}
[Property]
bool account_names_are_unique(List<Employee> employees)
{
var accountNames = employees.Select(AccountNameGenerator.Generate);
return accountNames.ContainNoDuplicates();
}
[Property]
bool account_names_are_case_insensitive_(Employee employee)
{
var accountName = AccountNameGenerator.Generate(employee);
var upper = accountName.ToUpper();
return AuthenticationSystem.Login(upper);
}
Read it as:
- Given a random number of random employees
- Generating the account name for each of them
-
Will result in no duplicates
- Given a random employee
- Generating their account name
- Login would work even using the upper-case version
I made use of some custom helper methods. This is something that happens often. And, yes: it also happens that I feel the need to cover those helper methods with tests. I do test my tests, why not?
Last example:
- We never apply more than 1 discount promotion
- we always select the most convenient discount
could be translated to:
[Property]
bool we_never_apply_more_than_1_discount_and_we_always_select_the_most_convenient_discount(List<Product> products, List<Promotion> promotions)
{
var cart = new Cart(promotions);
var total = cart.Checkout(products);
var theOtherTotals = promotions.Select(promotion =>
{
var singlePromotionCart = new Cart([promotion]);
return singlePromotionCart.Checkout(products);
}).ToList();
return
theOtherTotals.All(otherTotal => otherTotal >= total) &&
theOtherTotals.Any(otherTotal => otherTotal == total);
}
Read it as:
- Given an arbitrary set of Products and a arbitrary number of arbitrary Promotions
- Adding those Products to a Cart, with those Promotions enabled
- Then at checkout I will get a total.
- Comparing that total with what I would get from a Cart with any of
those Promotions taken individually:
- then, all the other promotions would be less convenient
- and there is one matching exactly what I was granted.
Wow, not as simple as mere example, I guess. But I imagine you see how they are all more general and rigorous, don’t you?
So, define Property-based Testing
Here’s the bold statement.
Property Testing is TDD on steroids.
It is about capturing the essence of business requirements —
rather than some arbitrary, often unmotivated examples — and
having them automatically tested as logical or mathematical
statements, more or less for free.
Too good. Where’s the catch?
You are right. It would be too good.
I see 3 catches.
First: Property-based Testing is not as easy as TDD.
It’s
hard to start with, and overtime it keeps being more challenging than
ordinary TDD. The libraries supporting it are usually more advanced,
as they generally require some knowledge of Functional Programming:
you should be prepared to have some understanding of how to write a
lambda, how to map it to a functor, what combinators are, how to
compose monads and the like.
But don’t despair: those are very
very rewarding challenges, you will enjoy them!
Second: figuring out which properties describe the business
behavior can be confusing.
Writing TDD tests is as easy as
finding a collection of reference use cases: the customer ordered an
apple (.5 EUR) and 3 books (10 EUR each), the total should be
30.5 EUR. Easy peasy.
Writing Property Tests for the same
e-commerce site is a different kettle of fish: it is not even clear
what a “property” is.
I’m afraid there are no silver bullets
here, besides elbow grease and a lot of experience.
Finally: PBT’s niche nature.
Compared to TDD, the
documentation is not likely copious and the typical examples you can
find online have often deceptively simple code, not directly
applicable to real-world use cases. If you are looking for answers to
your down-to-Earth needs, you will be disappointed to discover that
much of the documentation will teach you over and over how to test the
reversal of a list.
Finding a buddy for writing PBT in pair is
hard. Most likely, you will find resistance and skepticism.
That sucks, but it’s part of the challenge.
Say random again, say random again, I dare you!
Consider again the example I provided earlier:
[Property]
bool products_can_be_persisted(Product product)
{
_repository.Save(product);
var found = _repository.LoadById(product.Id);
return found == product;
}
When you run it, FsCheck will generate a comprehensive
number of randomly generated instances of Product.
You might think that PBT libraries are similar to
AutoFixture, and only useful for removing the need of
hard-coded values and making the Arrange phase easier.
But they
are not.
Let me stress this loudly: only at a first glance is Property-based Testing about generating random inputs. PBT is more about you and your conversation with the compiler, than it is about the test runner.
When the domain expert of an e-commerce company tells you:
Food products are restricted from international shipping due to regulatory compliance, unless there is an active Promotion.
and then you see an implementation such as:
if(product.Type == Food && order.Destination != LocalCountry)
throw new CannotBeSentException();
missing a check on an active Promotion, you sense there is a
bug.
You understand that, not because you mentally exercised the
code generating thousands of inputs, but because you are a sentient
being and you are able to use logic.
Compared to your brains, C# is dumb, therefore it has to resort to brute force.
But other approaches are possible. A library:
- could use logic reasoning, like in Prolog
- or rely on AI
- or have automated theorem provers like in Coq
- or infer the proper input values to input the test with, using Concolic Testing — a crazy approach with which the code is exercised with symbolic execution in conjunction with a resolver based on constraint logic programming. Have a look to Python’s CrossHair to see this in play.
It’s only incidental that your most beloved programming language is
bovine and has to wander around aimlessly with random inputs.
Property Testing is not defined by the limits of its libraries, just
like TDD is not merely what xUnit is capable of.
PBT is the act of writing requirements in their essence, as general specifications. The strategies the library uses to prove you wrong are an internal, incidental implementation detail.
Going Beyond Fixtures
Wow, if got this far, you must really be motivated. Let’s enter the rabbit hole.
Let me start from something you already know, and let’s try to build and motivate a PBT harness piece by piece.
In TDD you often desire to exercise a piece of code with multiple
input values, so to cover more than one single uses case.
Instead
of sticking with a single input:
[Fact]
void calcutates_the_sum_of_2_numbers()
{
var sum = add(2, 3);
Assert.Equal(5, sum);
}
you rather parametrize the test:
[Theory]
[InlineData( 2, 3, 5)]
[InlineData( 2, 0, 2)]
[InlineData( 0, 2, 2)]
[InlineData( 2, -2, 0)]
[InlineData(9999, -2, 9997)]
void calcutates_the_sum_of_2_numbers(int a, int b, int expectedSum)
{
var sum = add(a, b);
Assert.Equal(expectedSum, sum);
}
This is fine, although a bit tedious.
One problem with xUnit’s
InlineData is that it only works with constant values, which are
known at compile time. You can’t use instances of a class:
[Theory]
// This won't work
[InlineData(new Product(name: "Apple", category: Categories.Fruits, price: 0.90, description: "Delicious Fuji apple"))
[InlineData(new Product(name: "'Nduja", category: Categories.Sausages, price: 9.50, description: "Spicy. Original from Calabria"))
void discountable_products(Product product)
{
var discountIsApplyed = _catalog.CanBeDiscounted(product);
Assert.True(discountIsApplyed);
}
Sure enough, there are workarounds (see xUnit Theory: Working With InlineData, MemberData, ClassData), but this bears the questions:
- Are you sure the values of
descriptionandnameare relevant for those tests? Aren’t they just distracting? - Would it be a good idea to just have random values, for all the fields?
- Should those random data have any constraint, derived from the domain rules?
- How many different instances should be created to have a good use-case coverage?
- Are you sure you are not missing any important edge case?
In an ideal world, it would be nice if you could write something like:
[Property]
void any_product_classified_as_food_is_discountable([Food] Product product)
{
Assert.True(_catalog.CanBeDiscounted(product));
}
Notice the [Food] attibute, hypotetically instructing the library
what "product classified as food" means.
If we could write
that, there would be interesting consequences:
- the test would become independent from actual unnecessary values;
- explicitly referencing
Foodproducts, the test would be more expressive than a collection of specific cases; it would directly capture the business rule"Food products can be discounted" - The library would have the chance to discover that the case:
new Product(name: ___, category: Categories.SoftDrinks, price: ___, description: ___)}
fails.
Indeed, it would be super nice if the library could tell us:
I get the general rule. But, hey! I found a counterexample! Here it is:
new Product(name: ___, category: Categories.SoftDrinks, price: ___, description: ___)}
Don't even care about `name`, `price` and other fields: the element
causing the problem is
category = Categories.SoftDrinks
Apparently, the production code is not considering soft drinks as a food.
Either this is a bug, or your specification is incomplete.
Oh, cool! This would be much more than finding bug! It would be the beginning of a conversation in which you can reason about the correctness of both the code and the requirement.
As Joe Nelson wrote:
Proponents of formal methods sometimes stress the notion of specification above that of implementation. However it is the inconsistencies between these two independent descriptions of the desired behavior that reveal the truth. We discover incomplete understanding in the specs and bugs in the implementation. Programming does not flow in a single direction from specifications to implementation but evolves by cross-checking and updating the two. Property-based testing quickens this evolution. (from Design and Use of QuickCheck)
OK, but down to Earth: no Property-based Testing library is that smart. They are not too far, though. They can really shrink the counterexamples down, letting you focus on the minimum relevant values. We will see this in practice in the next paragraphs.
All right, but the [Food] attribute does not exist.
Yes, this is still hypothetical, we don’t have any [Food] attribute
yet. Solving this problem really isn’t impossible.
Let’s pause a moment to ruminate an intuition: this approach is likely to lead you to a big paradigm shift. Since the library takes away from you the control over which values to base your tests, this forces you to design your tests in a very different way.
Think to the initial, stupid sum example:
[Theory]
[InlineData( 2, 3, 5)]
[InlineData( 2, 0, 2)]
[InlineData( 0, 2, 2)]
[InlineData( 2, -2, 0)]
[InlineData(9999, -2, 9997)]
void calcutates_the_sum_of_2_numbers(int a, int b, int expectedSum)
{
var sum = add(a, b);
Assert.Equal(expectedSum, sum);
}
If you let a library randomly generate the test values:
[Property]
void calcutates_the_sum_of_2_numbers(int a, int b)
{
var sum = add(a, b);
Assert.Equal(???, sum);
}
you will have no possibility to write the assertion. No chances that
the expected value is also randomly generated.
Neither is using
a + b in the assertion a good choice:
[Property]
void calcutates_the_sum_of_2_numbers(int a, int b)
{
var sum = add(a, b);
Assert.Equal(a + b, sum);
}
Indeed, this mirrors the implementation, which completely defies the
idea of testing.
You are forced to think of some other property
which holds whatever the input. For example:
[Property]
bool sum_is_commutative(int a, int b) =>
add(a, b) == add(b, a);
[Property]
bool adding_zero_does_not_change_the_result(int a) =>
add(a, 0) == a;
I have chosen the silly sum example because it is the basis of the epic video The lazy programmer’s guide to writing thousands of tests by Scott Wlashlin. It’s a joy to watch.
As funny the sum example is, it is pointless for the real world cases. In more complex cases, you want to have tests such as:
[Property]
void account_name_is_unique(
[AllDifferent] Account[] existingAccounts,
[FormWithDuplicatedAccount] RegistrationForm form)
{
var validationResult = _register(form);
Assert.Equal(Error("Account already exists"), validationResult);
}
or
[Property]
void no_discounts_is_applied_to_carts_without_food(
[CartContainingNoFoodProducts] List<Product> products)
{
var plainSumOfPrices = products.Sum(p => p.Price);
_cart.Add(products)
var total = _cart.Checkout();
Assert.Equal(plainSumOfPrices, total)
}
Again, notice the fictional attributes.
I hope you get how paramount the generation of values is, in PBT. It’s time to talk about that.
Enough with fictional attributes
By now you should have built the intuition that just generating purely random values does not work. We need to craft quasi-random values, strictly satisfying some specific domain rules. Indeed, if also we had a test data generator, we need a way to instruct it which rules to stick to. Because, after all, requirements are all about domain rules.
What about replacing our fictional attributes with custom made functions?
[Fact]
void account_name_is_unique()
{
Account[] existingAccounts = GenerateAllDifferent();
RegistrationForm form = GenerateWithADuplicateFrom(existingAccounts);
_application.Accounts = accounts;
var validationResult = _register(form);
Assert.Equal(Error("Account already exists"), validationResult);
}
Better. But it’s a poor man’s solution, and we can surely do more.
I see the following traits:
-
It’s still unclear what’s inside those functions. So far, we just moved the problem one level up;
-
The test above only generates 1 set of random values. Ideally, we would like to generate thousands. Something like:
record Input(Account[] ExistingAccounts, RegistrationForm form)
[Fact]
void account_name_is_unique()
{
Input[] inputs = Generate(10_000);
inputs.ForEach(input =>
_application.Accounts = input.accounts;
var validationResult = _register(input.Accounts, input.Form);
Assert.Equal(Error("duplicated"), validationResult);
)
}
Notice how we needed a bit of boilerplate code to wrap the test inside a cycle.
- It might not be immediately apparent, but they way random values are
generated is not very reusable.
We wish we could write a second test elaborating the random existing accounts:
Account[] existingAccountsIncludingDisabledOnes =
GenerateAllDifferent()
.ComposedWith(HavingAtLeast3DisabledAccounts());
It’s unlikley that such a generic ComposedWith() method could be
defined. Maybe it could for collections, using LINQ: but extending
this idea to any possible type would be a tough challenge.
The problem is that our generator functions immediately return values.
Once we have values, it’s too late to modify the rules for generating
further ones.
If instead they returned structures capable of
eventually emitting values, such as wrappers of functions, you would
still be in time to alter the domain rules before finally generating
values.
You need a structure with solid compositional capabilities, such as a monad.
Now probably, I just lost half of my readers.
Test Data Generators
Great, still here, you brave! Let’s see how deep this rabbit hole is, then.
The canonical answer in the Property Testing world is to use Generators. You can think of a Generator as a code-based recipe for generating random data accordingly to some custom rules. So, not a trivial random value generator, but a much more advanced structure, able to support you with challenges like:
- generate odd numbers, starting from small ones, and exponentially
increasing them, up to the maximum value
N - generate instances of
Product, 30% of which with prices between10and100, the rest with lower prices - generate lists of
Products, without duplications, ordered bydescription, maximum 20 items - generate couples of
Products, whose price difference is between10and20, with samedescriptionbut differentcategory, picked from the optionsBook, Other, Laptoponly - generate a cart, containing up to
10Products, without exceeding the total of100 EUR.
There is virtually no limit to the complexity you want to cover. We clearly need a language to express those domain rules.
Prior randomized testing tools required learning a special language and grammar to program the generation of complex test cases. QuickCheck was the first library providing an embedded Domain Specific Language (heavily based on Haskell’s amazing type system), in the very same language tests are written in, for writing the test data generation specifications.
As everything in Functional Programming, the secret is to start simple. Imagine having:
- a structure able to generate random booleans:
Arb.Generate<bool> - another able to generate random characters:
Arb.Generate<char>
and then being able to create new more complex building blocks composing the smallest ones:
- an generator of strings built as a composition of char generators:
Gen.ListOf(Arb.Generate<char>).Select(string.Concat) - The generator for the record
record Product(Guid Id, string Name, Category Category, decimal Price);built composing the generators for names, prices and categories, no matter how they are defined, with:
Gen<Product> products =
from id in Arb.Generate<Guid>()
from name in Arb.Generate<string>()
from price in Arb.Generate<decimal>()
from category in Arb.Generate<Category>()
select new Product(Id: id, Name: name, Price: price, Category: category);
Usually, the algebra to use is the one for monadic composition, with the syntax offered by your language of choice.
Let’s have a look to some real examples.
This generates a random boolean values, with equal probability:
Gen<bool> equallyDistributedBooleans =
Arb.Generate<bool>();
This generates random boleans weighting the probability of choosing each alternative by some factors:
Gen<bool> tenMoreTrueValuesThanFalseOnes =
Gen.Frequency(new Tuple<int, Gen<bool>>[]
{
new(10, Gen.Constant(true)),
new(1, Gen.Constant(false))
});
Notice how both are Gen<bool>: you can manipulate both of them
consistenly.
This emitting tuples of values bewteen 1 and 100, with the
restriction that the two elements in each tuple must be different:
var tuplesWithDifferentElements =
Gen.Two(Gen.Choose(1, 100))
.Where(t => t.Item1 != t.Item2);
The following generates Users whose FirstName is one of "Don",
"Henrik" or null, a LastName with one of "Syme" and "Feldt"
(but never null), and an id between 0 and 1000:
record User(int Id, string FirstName, string LastName);
Gen<User> users =
from fistName in Gen.Elements("Don", "Henrik", null)
from secondName in Gen.Elements("Syme", "Feldt")
from id in Gen.Choose(0, 1000)
select new User(id, firstName, secondName);
That’s an example from Johannes Link’s Property-based Testing in Java, based on jqwik:
@Provide
Arbitrary<Person> validPerson() {
Arbitrary<String> firstName = Arbitraries.strings()
.withCharRange('a', 'z')
.ofMinLength(2).ofMaxLength(10)
.map(this::capitalize);
Arbitrary<String> lastName = Arbitraries.strings()
.withCharRange('a', 'z')
.ofMinLength(2).ofMaxLength(20);
return Combinators.combine(firstName, lastName).as(Person::new);
}
@Property
boolean anyValidPersonHasAFullName(@ForAll("validPerson") Person aPerson) {
return aPerson.fullName().length() >= 5;
}
I bet it does not need comments to be understood: it’s almost narrative English.
Finally, this one in Haskell generates random images like:
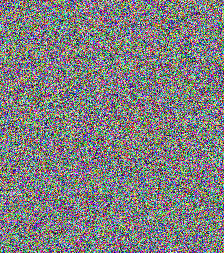
instance Arbitrary PixelRGB8 where
arbitrary = PixelRGB8 <$> arbitrary <*> arbitrary <*> arbitrary
genImage :: Gen (Image PixelRGB8)
genImage = do
f <- arbitrary
(x, y) <- arbitrary `suchThat` ( \(x,y) -> x > 0 && y > 0 )
return $ generateImage f x y
I don’t expect you to fully understand the code above yet. Just focus on the key messages:
- Generators are composable structures. Each language would use its own tricks: in C# they are classes.
- They are natively written in your preferred language. No extra languages to learn.
- They are compositional in nature. Combining Generators gives you another Generator. It’s Generators all the way down.
- Once you understand the mechanic behind composing them, you’ve broken every limit. Composing stuff requires a bit of Functional Programming. This is where the fun begins.
Oh, wait: I forgot to mention that Properties too are made of composable structures.
So, in a sense, Property-based Testing is about decomposing the problem-space of the domain into small properties and generation rules, and then about describing the business functionalities as a composition of those building blocks, for an automated library to challenge you.
It’s time to see some code. Take 5 minutes to have an icecream and when ready jump to the second installment.
References
See References
Comments
Functional Programming For The Rest Os Us
Interested in FP? Be the first to be notified when new introductory
articles on the topic are published.